Sorting the digitized data
COBECORE aims to transcribe historical climate data. Sadly the volume as well as the state of the documents limits automation of this process. As such, we aim to enlist the help of citizen scientists to contribute a bit of time to transcribe this data. However, even these efforts require the original scans to be sorted and pre-processed. Doing so revealed some interesting statistics.
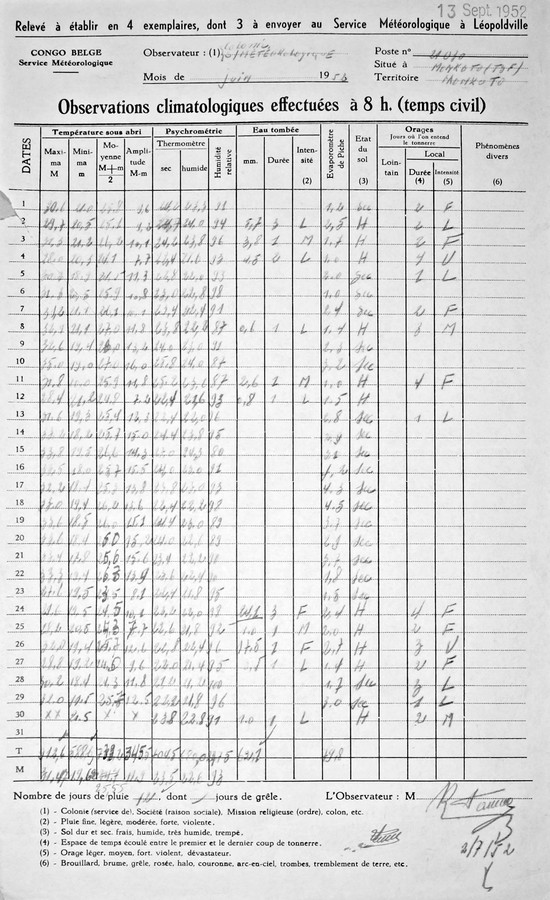
Most of the data is stored two formats, a larger and a smaller table (see Fig 1.). These datasets are good for 14.8K and 24.7K images respectivelly. The next steps will include dividing these sheets in particular into their individual cells. Afterwards these cells will be (automatically) scanned for the content of data. Those containing data will be shown to citizen science for transcription.
 |
BLOG
data_recovery digitization citizen_science